
Given two input images, our approach can generate a smooth and natural transition video between them.
This is achieved purely by leveraging the prior knowledge of a pre-trained diffusion model, i.e., Stable Diffusion.
Diffusion models have achieved remarkable image generation quality surpassing previous generative models. However, a notable limitation of diffusion models, in comparison to GANs, is their difficulty in smoothly interpolating between two image samples, due to their highly unstructured latent space. Such a smooth interpolation is intriguing as it naturally serves as a solution for the image morphing task with many applications. In this work, we present DiffMorpher, the first approach enabling smooth and natural image interpolation using diffusion models. Our key idea is to capture the semantics of the two images by fitting two LoRAs to them respectively, and interpolate between both the LoRA parameters and the latent noises to ensure a smooth semantic transition, where correspondence automatically emerges without the need for annotation. In addition, we propose an attention interpolation and injection technique, an adaptive normalization adjustment method, and a new sampling schedule to further enhance the smoothness between consecutive images. Extensive experiments demonstrate that DiffMorpher achieves starkly better image morphing effects than previous methods across a variety of object categories, bridging a critical functional gap that distinguished diffusion models from GANs.
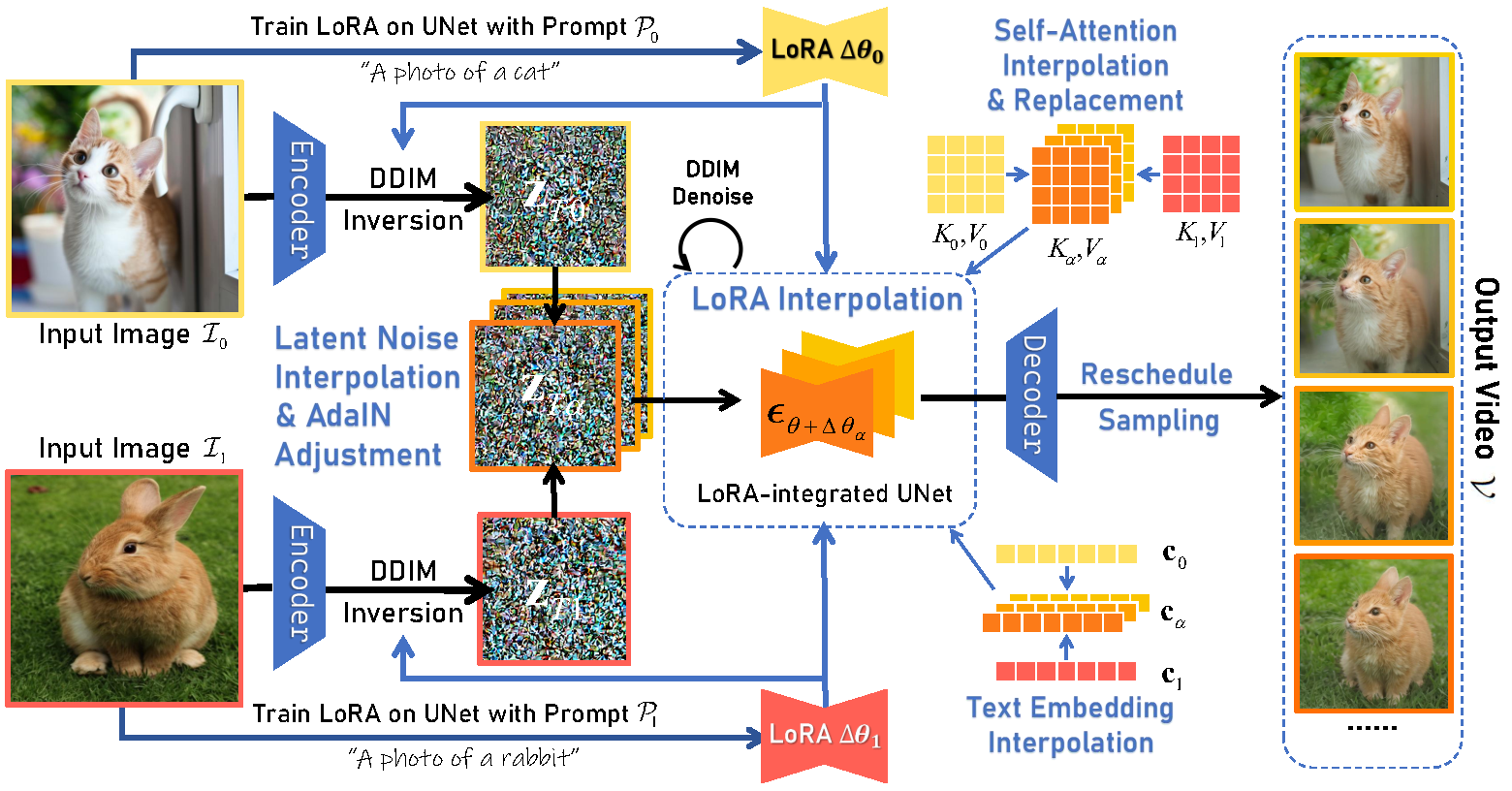
Given two images I0 and I1, two LoRAs are trained to fit the two images respectively. Then the
latent noises for the two images are obtained via DDIM inversion. The mean and standard deviation of the interpolated
noises are adjusted through AdaIN. To generate an intermediate image, we interpolate between both the LoRA parameters
and the latent noises via the interpolation ratio α. In addition, the text embedding and the K and V in
self-attention modules are also replaced with the interpolation between the corresponding components.
Using a sequence of α and a new sampling schedule, our method will produce a series of high-fidelity images
depicting a smooth transition between I0 and I1.
@article{zhang2023diffmorpher,
title={DiffMorpher: Unleashing the Capability of Diffusion Models for Image Morphing},
author={Zhang, Kaiwen and Zhou, Yifan and Xu, Xudong and Pan, Xingang and Dai, Bo},
journal={arXiv preprint arXiv:2312.07409},
year={2023}
}